lodplatform
LOD-GF: An Integral Open Data Generation Framework
LOD-GF
Linked Open Data Platform: Solution to accomplish the life cycle management for publishing Linked Data on the Web.
Contenido
Introducción
Con el avanzar del tiempo un número mayor de empresas e instituciones se han ido sumando a la iniciativa de Linked Open Data, atraídos por las múltiples ventajas que esta tecnología aporta tanto en la reutilización, integración y el aprovechamiento superior de la información. Sin embargo, aunque esta tecnología ha ido creciendo constantemente, aun debe superar serios factores que afectan su adopción generalizada. Dentro de estos factores se encuentran la necesidad de conocimiento avanzado acerca de tecnologías semánticas, así como la falta de herramientas que soporten el proceso de generación y publicación de Linked Data. Para afrontar esta problemática ha surgido LOD-GF, el cual es un framework basado en Pentaho Data Integration que brinda un entorno unificado para el soporte de cada una de las fases de la metodología de publicación de Linked Open Data.
Para soportar cada una de estas fases el framework emplea plugins (módulos de procesamiento especializados) tanto nativos de este entorno como desarrollados para brindar un marco de trabajo gráfico y flexible, con el cual los usuarios puedan convertir sus datos originarios de un amplio dominio de fuentes o formatos a datos enlazados de calidad.
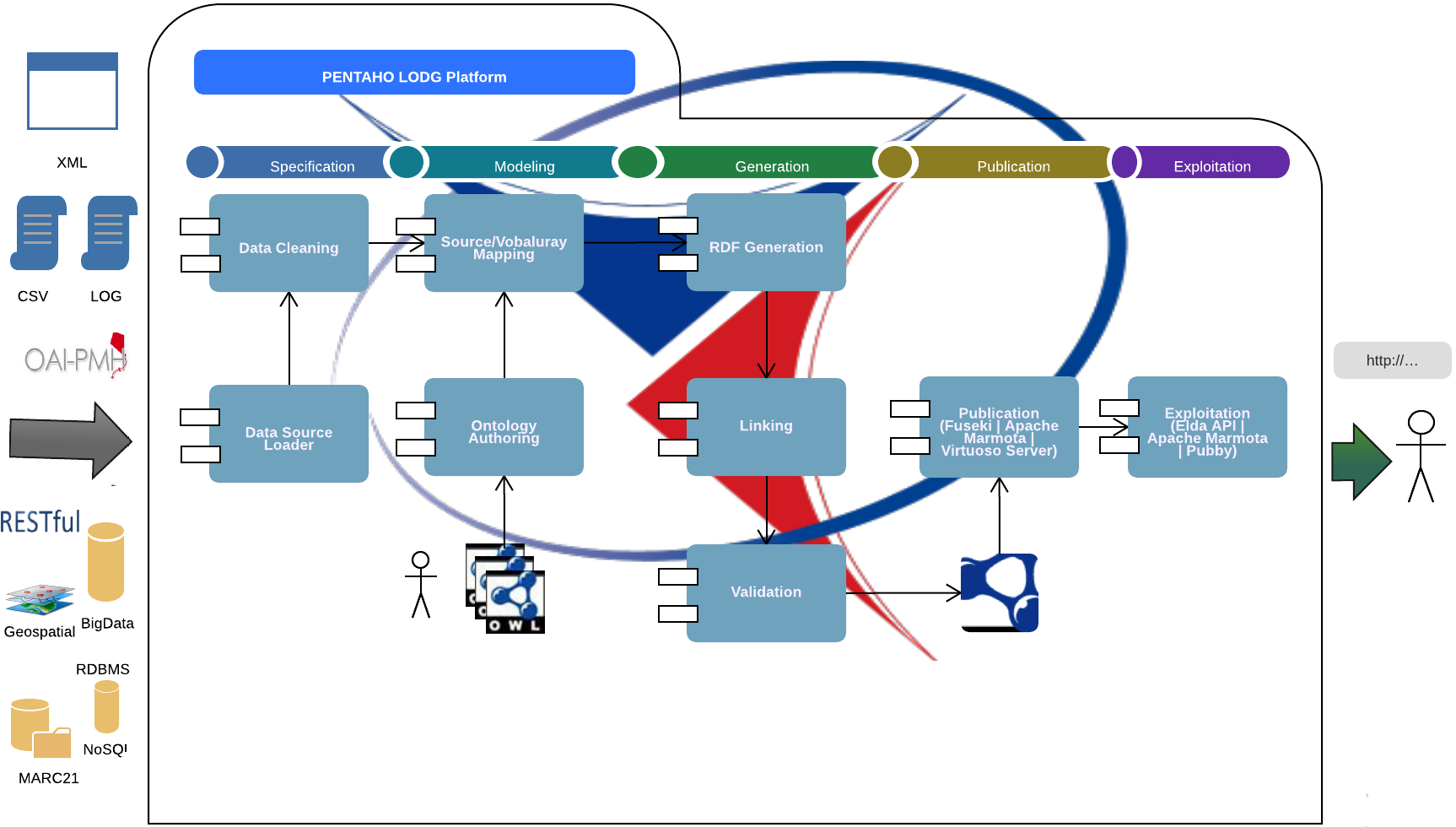
LOD-GF es amigable al usuario gracias a su interfaz gráfica y sus mecánicas drag&drop heredadas de Pentaho Data Integration (PDI). Para que el framework pueda soportar el proceso de generación y publicación de LOD, adicionalmente a los plugins nativos que cuenta PDI , se han generado plugins especializados haciendo que juntos satisfagan las necesidades presentadas en cada una de las fases de la metodología.
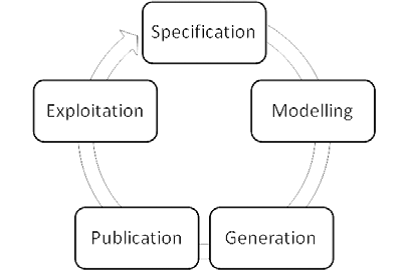
Fases del proceso de publicación de datos enlazados
A continuación se detalla cada una de las fases del proceso de publicación de datos enlazados y así como los componentes del framework que se emplea para soportarlas.
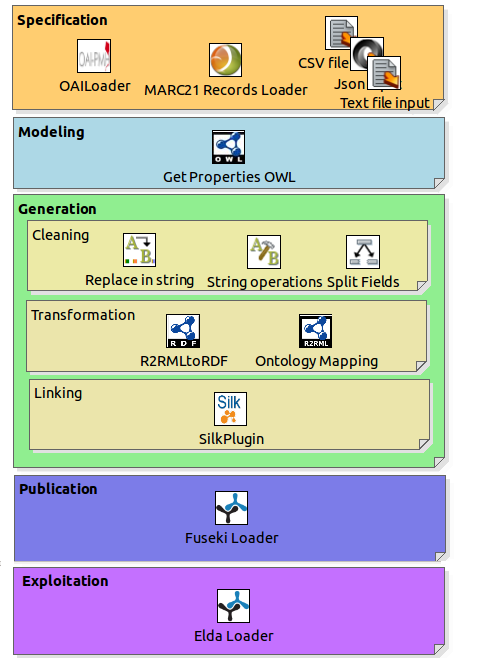
1. Especificación
Esta etapa principalmente se centrar en definir las fuentes de los datos que seran procesados y convertidos siguiendo los principios de Linked Open Data. Para este proceso el framework ofrece varios plugins para la lectura de datos sobre distintas fuentes (base de datos, servicio web, etc), así como el procesamiento de distintos formatos de datos (csv, excel, json, xml, etc).
| Plugin | Soporte |
|---|---|
 |
Lectura de archivos de texto |
 |
Lectura de archivos separados por comas |
 |
Lectura de archivos XML |
 |
Lectura de tablas de base de datos |
 |
LLamada de servicios web en diversos formatos |
 |
Entrada de datos desde archivos Excel |
La mayoría de los plugins que pueden ser empleados en esta fase son propios de Pentaho, sin embargo para casos particulares es posible desarrollar plugins personalizados. En este caso se han desarrollado dos plugins especiales orientados a la lectura de recursos bibliográficos.
| Plugin | Soporte |
|---|---|
 |
El protocolo OAI-PMH es un mecanismo adoptado ampliamente por repositorios digitales para la comunicación y cosecha de metadatos. Mediante el plugin OAI-LOADER es posible acceder a los servicios de los repositorios digitales como DSPACE para la extracción de metadatos. |
 |
Este plugin permite la lectura de metadatos de recursos bibliográficos que se encuentren en formato MARC 21. Este formato es ampliamente empleado para el almacenamiento y transferencia de recursos bibliográficos tanto físicos como digitales debido a la gran cantidad de campos especializados que dispone. |
Para obtener más información acerca del funcionamiento y configuraciones de los plugins de lectura, acceder a la sección del manual
2. Modelamiento
En esta etapa se debe identificar, seleccionar o generar vocabularios que permitan describir semánticamente los datos de las fuentes disponibles de acuerdo a su dominio. En este caso el framework provee el plugin llamado Get Properties OWL con el cual se puede cargar los vocabularios de ontologías tanto de las que se encuentran disponibles en la web, como las creadas localmente. Para esto brinda dos tipos de carga:
- Archivo: Carga los vocabularios desde un archivo con formato compatible con la definición de esquemas ontológicos por ejemplo OWL.
- Web : Es posible cargar vocabulario ontológico definiendo unicamente su prefijo. Ejemplo foaf, dcterms, etc.

Este plugin sirve como paso previo al proceso asignación de vocabularios (Mapping) en la fase de generación.
Información acerca de la interfaz y configuración de este plugin en la sección del Modelamiento del manual.
3. Generación
El objetivo central de esta etapa es la conversión de datos a formato RDF, para lo cual se consideran aspectos como la fiabilidad de los datos y la detección de recursos similares entre fuentes. Para llevar a cabo este objetivo por lo tanto, se realizan varias actividades tales como limpieza de datos, conversión de datos a formato RDF y generación de enlaces.
3.1 Limpieza de datos
Una actividad importante en el proceso de generación de datos enlazados es la limpieza de datos. Dentro de esta actividad se adecuan, estandarizan y aseguran la calidad mínima de los datos para poder generar datos enlazados de calidad. Para realizar esta actividad el framework posee un desempeño destacable al estar basado en una herramienta ETL que dispone de varias componentes nativos para la transformación, estandarización y en general procesamiento de datos. Dentro de los plugins más empleados en esta etapa están:
| Plugin | Soporte |
|---|---|
 |
Brinda la posibilidad de realizar reemplazos sobre cadenas de caracteres, con lo cual se puede eliminar caracteres desconocidos o erróneos. |
 |
Se puede utilizar cuando se tiene más de un tipo de información en un campo y se requiere separarla. |
 |
Con este plugin se pueden mapear valores de los campos con otros, lo cual es útil cuando se quiere realizar estandarizaciones. |
 |
Permite realizar operaciones con cadenas de caracteres, como remover números, eliminar caracteres especiales, quitar espacios en blanco entre otros. |
Una vez los datos han sido procesados, se dispone de un plugin de almacenamiento temporal Data Pre catching que permite que los datos ya procesados liberen la memoria y puedan ser manipulados en los pasos posteriores.

3.2 Conversión de datos
Una vez los datos han sido acondicionados y se encuentran libres de errores se procede a describirlos semánticamente empleando los vocabularios de las ontologías previamente cargadas. Para realizar este proceso se dispone de un plugin llamado Ontology & Data Mapping ,el cual permite vincular a los recursos con determinado vocabulario semántico. Dicha vinculación (Mapping) funcionan como reglas con lo cual los datos serán descritos automáticamente siguiendo el estándar RDF.

Dentro de este proceso se distinguen 3 diferentes procesos de mapeo:
-
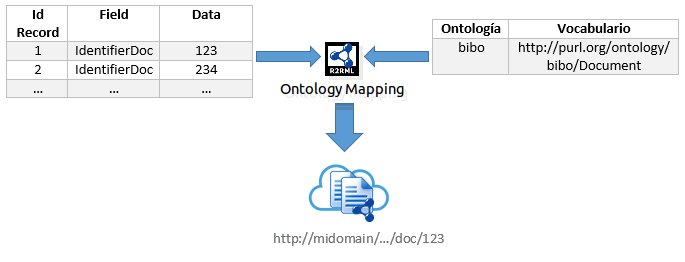
Mapeos de Clasificación: En este se definen los registros o datos como un tipo específico de recurso. Ejemplo
-
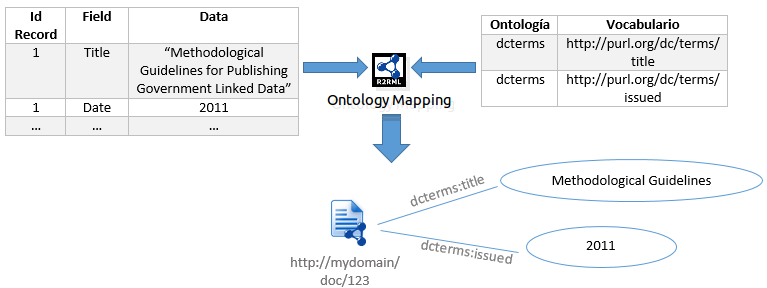
Mapeos de Propiedades: Mediante esta opción se asocian propiedades obtenidas de los datos a los recursos definidos anteriormente. Ejemplo.
-
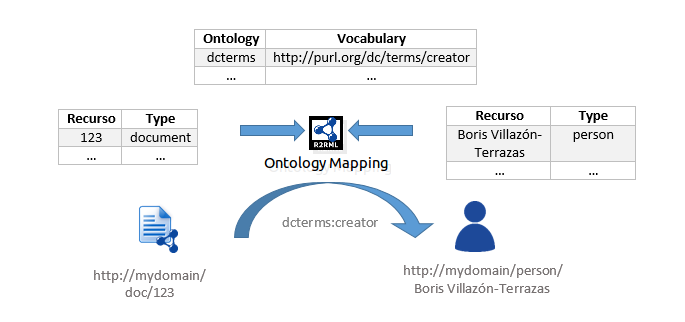
Mapeos de Relación: Permite especificar relaciones entre recursos. Por ejemplo.
Una vez se han generado los archivos de mapeo, estos deben ser ingresados en otro plugin (R2RMLtoRDF) que permite que las reglas definidas se apliquen sobre los datos para finalmente obtener estos datos en un archivo RDF. Mediante el plugin se puede representar los datos con la sintaxis RDF-XML, N3, Turtle, etc.

Más detalles acerca de la interfaz y configuración de los plugins de generación en la sección del manual Generación.
3.3 Enlace (Linking)
Para aprovechar de todas las características y ventajas que ofrece las tecnologías de Linked Data, es necesario generar enlaces entre recursos de distintas fuentes. Esto permite que la información se enriquezca con cada fuente disponible y aumenten la cantidad de información que se puede extraer. Para el enlace de datos se ha desarrollado un plugin específico (Silk Plugin) que permite utilizar la potencialidad de SILK Workbench de forma integrada y sencilla para encontrar los recursos similares entre dos fuentes. Por ahora este plugin funciona únicamente para realizar proceso de enlace entre autores y se destaca por contar con un proceso de validación mediante desambiguación semántica. En el proceso de desambiguación los autores son caracterizados por sus obras para posteriormente generar una métrica semántica de similitud, que determinara si dos autores hacen referencia o no a una misma persona.

Más detalles acerca del plugin de enlace y desambiguación en la sección del manual Enlace.
4. Publicación
En esta etapa se centran los esfuerzos en mejorar la visibilidad de los datos obtenidos de la etapa de generación, para que puedan ser consumidos por las entidades interesadas. Para llevar a cabo esta tarea se almacenan regularmente los datos en un triplestore que generalmente dispone de un medio de acceso a los datos (Sparql Endpoint). Para solventar esta fase, el framework dispone de un plugin especializado conocido como Fuseki Loader, el cual permite configurar los parámetros básicos para el despligue del triplestore Fuseki con los datos generados del proceso anterior. Así mismo, es posible configurar un punto de acceso a los datos para que puedan ser consumidos desde la web.
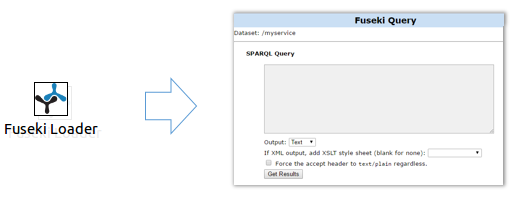
Mas detalles acerca del plugin de publicación, en la sección del manual Publicación.
5. Explotación
Esta etapa contempla el uso o desarrollo de herramientas, en función de mejorar el aprovechamiento de los datos generados orientado a los usuarios. En este caso se dispone del plugin ELDA Loader, el cual ofrece la posibilidad de generar una página de descripción de los recursos, en la cual se puede consumir y navegar por la información generada en formato RDF de una forma más amigable al usuario.
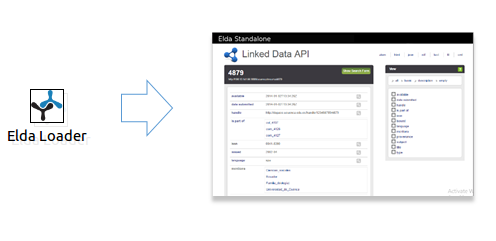
Mas detalles acerca del plugin de explotación en la sección del manual Explotación. Ejemplo
DEMO
Una demostración del funcionamiento del framework para repositorios digitales, se puede ver en el siguiente enlace:
Un ejemplo completo de aplicación de repositorios digitales se puede encontrar en la sección de ejemplo. Mas detalles acerca del plugin de explotación con otros casos de uso se pueden encontrar en el reporte técnico en el siguiente enlace (Disponible únicamente en español).
AGRADECIMIENTOS
Se agradece al departamento de Ciencias de la Computación de la universidad de Cuenca, así como a RED-CEDIA por el apoyo brindado al presente proyecto.

The project guarantees a continuous Integration using Codeship.