lodplatform
LOD-GF: An Integral Open Data Generation Framework
COMPONENTES ESPECIALIZADOS DEL FRAMEWORK
FASE DE ESPECIFICACIÓN
OAI-PMH Loader
Este plugin permite la lectura de repositorios digitales que dispongan del servicio OAI-PMH.
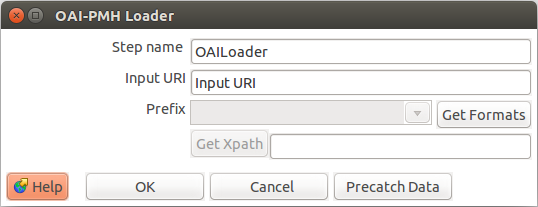
- Input URI: Ruta de acceso al servicio OAI-PMH perteneciente al repositorio.
- Prefix: Específicación del formato de lectura que puede ser extraído con el servicio, por ejemplo OAI-DC o XOAI.
- GetXPATH: Ruta desde la cual se empezara a leer la información.
MARC Input
Plugin para la lectura de registros desde ficheros en formato MARC 21.
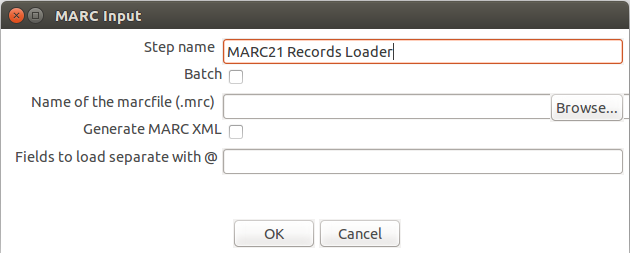
- Batch: Opción que permite la lectura de varios archivos dentro de un directorio.
- Name of the marcfile: Ubicación del archivo con extensión Marc 21 para su lectura.
- Generate Marc XML: Esta opción permite exportar la información del fichero MARC a XML.
- Field to load separate with @: Permite definir los campos marc 21, que seran extraídos del fichero. Para definir varios campos se requiere separarlos mediante @.
FASE DE MODELAMIENTO
GET PROPERTIES OWL
Carga los modelos ontológicos y su vocabulario
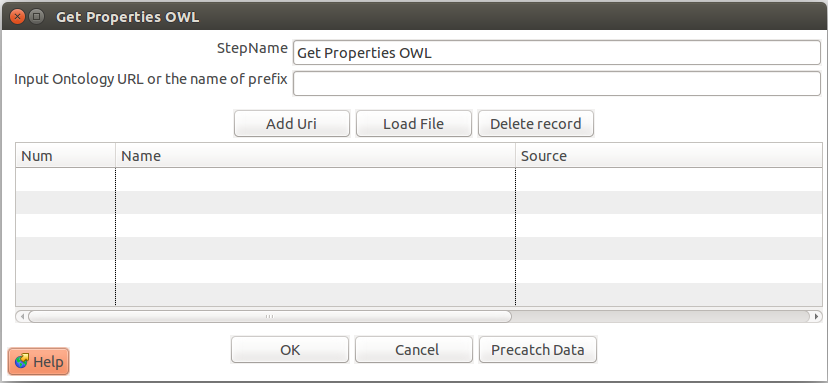
- Input URL or the Name of Prefix: En este campo se puede ingresar la URL completa de la ontología o su prefijo. Para verificar el prefijo de una ontologia revisar la página prefix
- Add URI: Mediante este botón se puede cargar la ontología definida en el campo anterior.
- Load File: Despliega un ventana en la cual se puede ingresar la ruta del archivo que contiene la ontología.
- Delete Record: Permite borrar una ontología seleccionada en la grilla inferior.
- Precatch Data: Con esta opción se puede precargar el vocabulario en el framework y facilitar el acceso a los atributos de la ontología en el componente Ontology&DataMapping
FASE DE GENERACIÓN
Data Pretcaching
Este plugin es empleado para guardar temporalmente los datos luego del proceso de limpieza y facilitar su lectura desde los plugins de Mapping (Ontology&DataMapping) y generación (RDF GENERATION) de RDF.
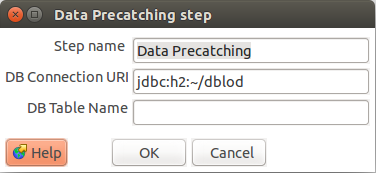
- DB Connection URI: Ruta de la base de datos h2 que almacenara los datos.
- DB Table Name: Nombre de la tabla que almacenara los datos.
*En caso de no realizar cambios, se tomara una configuración por defecto.
Ontology & Data Mapping
Permite definir los reglas de asociación de los datos de las fuentes con el vocabulario ontológico seleccionado. Dentro de las configuraciones del plugin se pueden distinguir dos partes:
Configuraciones Generales
Estas configuraciones se enfocan en ajustes generales del propio plugin, necesarios para la posterior generación de configuraciones específicas del mapeo. Dentro de estos campos podemos encontrar:

- Ontology Step: En este campo se debe ingresar la denominación asignada al plugin GetPropertiesOWL. Al definir este plugin se pueden cargar los vocabularios dentro del proceso de mapeo.
- Data Step: En este campo se debe ingresar la denominación asignada al plugin de cache Data Precatching que contiene los datos de las fuentes.
- Data Base URI: Definición de la URI absoluta con la que se generarán los nuevos recursos. Es recomendable que apunte a una dirección web en la que se puede encontrar descripción del recurso.
- Output Directory: Ruta en la cual se almacenara el archivo de mapeo generado en sintaxis R2RML.
Configuraciones Específicas de Mapeo
Adicionalmente a las configuraciones generales, el plugin dispone de configuraciones específicas dependiendo del tipo de mapeo que se esta realizando. Entre este tipo de mapeos se encuentra:
Configuración de Entidades (Classification)
En este se definen los registros o datos como un tipo específico de recurso.

- ID: Un identifícador que se genera automáticamente para identificar el mapeo definido de entidades.
- Ontology/ Entity: Nombre de la ontologia y el vocabulario específico con el cual se relacionara un registro para definirlo como recurso. Ejemplo: foaf/foaf:person
- Relative URI: URI relativa que se complementara con la URI absoluta para formar la URI del recurso. Por ejemplo (persona/)
- URI Field ID: Campo de los registros dentro del flujo que pasara a convertirse en el identificador único de cada recurso. Por ejemplo Data: Nombre.
- Data Field/Data Value : Campo y valor que debe tener un registro para que sea considerado en el mapeo. Por ejemplo Field/Autor
Configuración de Propiedades (Annotation)
Mediante esta opción se asocian propiedades obtenidas de los datos a los recursos definidos anteriormente.

- EntityClassID: Permite definir el ID de la entidad mapeada con la cual se relacionaran las propiedades declaradas.
- Ontology/ Property: En estos campos se definen la ontología y el vocabulario que se usa para representar la relación de propiedad. Ejemplo: foaf/foaf:name
- Extraction Field: Campo del registro del cual tomara el valor la propiedad. Por ejemplo Data: Antonio Ramirez.
- Data Field/Data Value : Campo y valor que debe cumplir el registro para aplicarse la regla de mapeo por propiedad. Ejemplo: Field /Nombre del autor.
- Data Type: Definición del tipo de dato que representa la propiedad. Por Ejemplo: String.
Configuración de Relaciones (Relation)
Permite especificar relaciones entre recursos.

- ID: Un identifícador que se genera automáticamente para identificar el mapeo definido para definir las relaciones entre recursos. EntityClassID 1 / EntityClassID 2 : Permite definir el ID de la primera y segunda entidad que van a ser relacionadas. Si se coloca una
- Ontology/ Property: En estos campos se definen la ontología y el vocabulario con el cual se identificara la relación. Ejemplo (dcterms/dcterm:contributor)
RDF GENERATION
Este plugin aplica las reglas definidas en el proceso de mapping a los datos para obtener el archivo descritos como RDF.
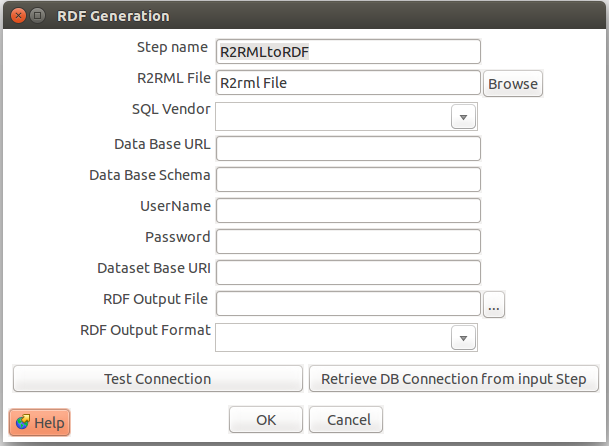
- R2RML File: Permite definir la ruta del archivo R2RML generado en el plugin anterior.
- SQL Vendor: Con esta opción se puede seleccionar el proveedor de la base de datos. Por defecto es H2.
- Data Base URL: Ruta de la base de datos donde se encuentra los datos transformados en cache.
- Data Base Schema: Esquema de la base de datos.
- Username/Password: Credenciales para acceder a la base de datos.
- Data base URI: URI absoluta para los recursos.
- RDF output File: Ruta de salida con el archivo RDF.
- RDF output Format: Formato específico en el cual se generara el RDF. (Disponible XML y TTL).
- Retrieve DB connection from input step: Con este botón podemos recuperar las configuraciones de base de datos realizadas en el plugin Data Precatching.
LINKING SILK PLUGIN
Permite descubrir enlaces de similaridad entre recursos. Por el momento, funciona para descubrir enlaces entre autores de diferentes fuentes en base a sus documentos.
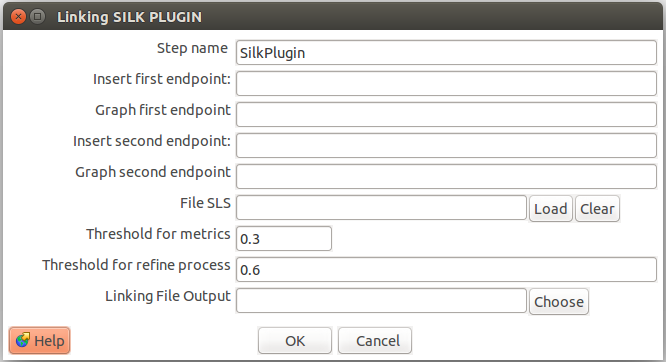
- Insert First Endpoint/Graph: Sirve para definir el primer endpoint o endpoint base y su grafo con el cual se ejecutara el proceso de Linking.
- Insert Second Endpoint/Graph: Sirve para definir el segundo endpoint o endpoint objetivo y su grafo con el cual se ejecutara el proceso de Linking.
- File SLS (Opcional) : Con esta opción se puede cargar directamente un archivos SLS de SILK que contenga las configuraciones que se desean ejecutar.
- Threshold for metrics: Permite definir el umbral de la métrica de similitud empleado en el proceso de encontrar recursos similares.
- Threshold for refine process: Permite definir los umbrales para el proceso de validación empleando metricas semánticas.
- Linking File Output: En este campo se define la ruta con los resultados del proceso de enlace.
FUSEKI LOADER
El plugin de Fuseki permite desplegar un triplestore fuseki para almacenar los datos generados como RDF y brindar un servicio de acceso SPARQL Endpoint.
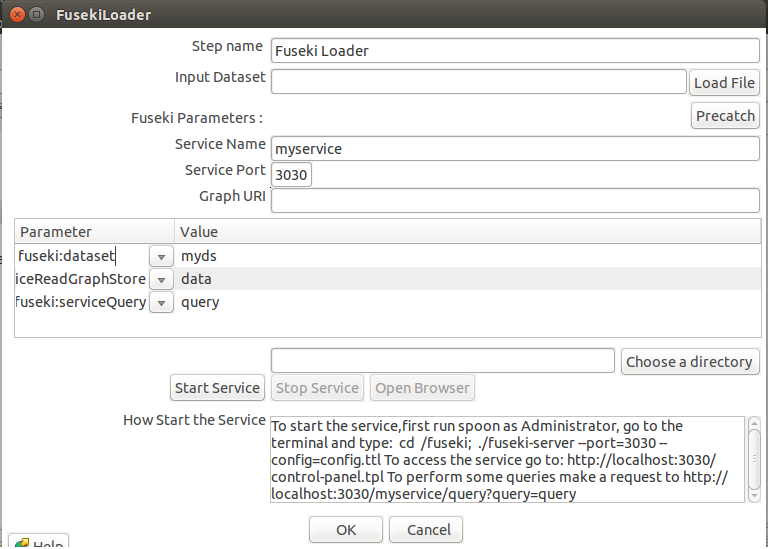
- Input Dataset: En este campo se define la ruta del archivo que se desea almacenar y desplegar en fuseki.
- Service Name: Campo opcional en donde se define el nombre que se le puede dar al servicio.
- Service Port: Puerto por el cual se puede acceder al servicio.
- Graph URI: Sirve para definir un grafo en el cual almacenar la información dentro del triple-store.
- Choose Directory : Permite definir la ruta de salida de la aplicación Fuseki.
- Grilla de configuración : En esta sección se pueden definir reglas que se aplicarán al almacenar los datos en el triple-store Fuseki.
ELDA LOADER
Este plugin permite configurar y desplegar el servicio de API ELDA, el cual ofrece una interfaz de descripción de los recursos en la web de datos publicados como RDF en los SPARQL ENDPOINT.
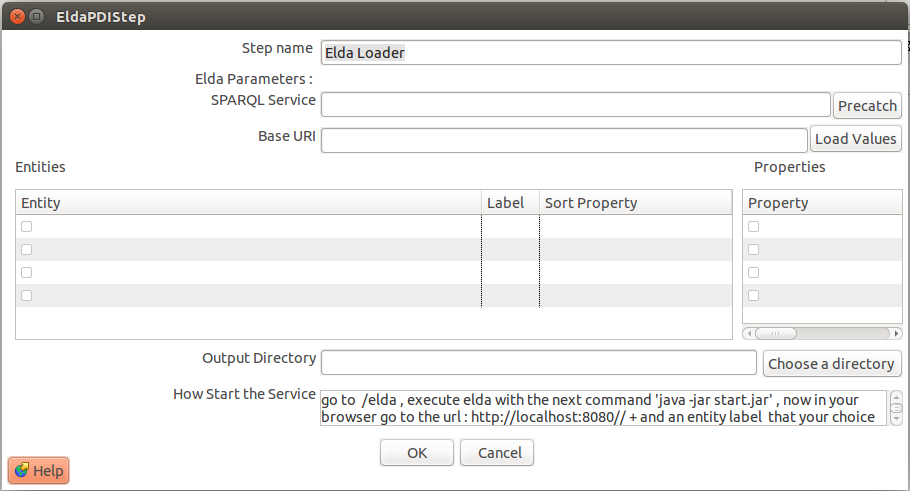
- Sparql Service: Endpoint Sparql del cual se tomara los datos.
- Base URI: URI del grafo en el cual se encuentran los datos que se desean explotar.
- Load Values: Carga los datos (entidades y propiedades) de una fuente en la grilla de configuración.
- Output directory: Ubicación de salida del software ELDA configurado y listo para ser desplegado.
- Grillas de configuración: En esta sección se pueden seleccionar las elementos encontrados en el endpoint (entidades y propiedades) que se desean visualizar mediante ELDA. Además es posible renombrar en la columna “Label” los elementos seleccionados para facilitar su interpretación por el usuario.