lodplatform
LOD-GF: An Integral Open Data Generation Framework
Generación de Linked Data a partir de un repositorio digital Dspace
En este ejemplo se presentan los pasos y configuraciones necesarias que han sido aplicadas sobre el framework para la generación y publicación de datos enlazados a partir del repositorio digital Dspace de la universidad de Cuenca. Este caso de uso es una muestra de aplicabilidad real del framework sobre varios escenarios y dicho procedimiento ha sido extendido sobre un gran número de universidades del país. Dentro de este tipo de repositorios se pueden encontrar la mayoría de documentación generada por las universidades entre los que se encuentran tesis, artículos científicos, revistas, etc. los cuales con la finalidad de mejorar su visibilidad e interoperabilidad han sido publicados siguiendo los principios de Linked Data.
Especificación
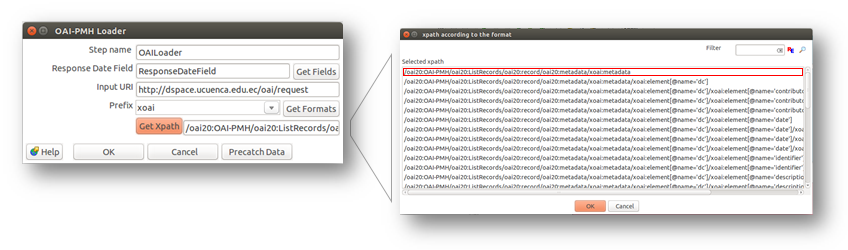
La mayoría de repositorios digitales como el tratado en este ejemplo, disponen de un servicio de cosecha OAI-PMH para la extracción de información. Dentro del framework para este tipo de fuentes se cuenta con el plugin especializado de lectura de servicios OAI-PMH conocido como “OAI-PMH Loader”. Como primer paso para configurar dicho plugin se coloca la URL del servicio OAI (http://dspace.ucuenca.edu.ec/oai/request) en el campo Input URI. Una vez hecho esto se puede seleccionar los formatos específicos para lectura mediante el botón Get Formats que despliega los prefijos de los formatos disponibles para extracción de los datos. En este caso se ha seleccionado XOAI. Adicionalmente, se selecciona el path de respuesta desde el cual se tomará los datos. Generalmente se debe tomar la primera opción, que se encuentra marcada en la figura 1. Finalmente, se acepta los cambios y se guarda la configuración.
Modelamiento
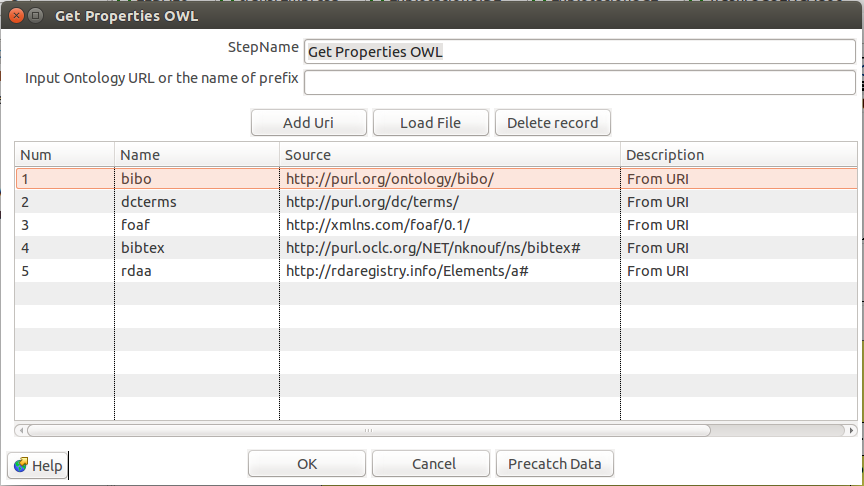
Para esta etapa se utiliza el plugin “Get Properties OWL” que se encarga de cargar los vocabularios de las ontologías. En este caso se han seleccionado varias ontologías que permiten describir semánticamente los diferentes recursos que disponen los repositorios. Entre estos se encuentran:
- bibo: Empleado para describir recursos bibliográficos.
- foaf: Utilizado para describir personas, objetos y propiedades asociadas.
- dcterms: Vocabulario empleado para describir algunas propiedades asociadas a documentos.
- bibtex: Dispone de algunos vocabularios específicos enfocados en describir referencias de recursos bibliográficos.
- rdda: Contiene vocabulario especializado para describir elementos relacionados con bibliotecas.
Para ingresar los vocabularios de las ontologías dentro del plugin, se puede optar por dos alternativas: usar un prefijo de la ontología o cargar un archivo con el modelo. En este caso se ha optado por la manera más sencilla que es ingresar el nombre o prefijo en el campo de “Input Ontology URL or the name of prefix” y cargar los datos mediante el botón “Add URI”. Una vez se ha realizado el proceso con todas las ontologías disponibles se puede precargar los datos con el botón “Pre-cath data” para ser utilizados posteriormente.
Generación
Dentro de la fase de generación se dispone de varias actividades, que pueden ser llevadas a cabo mediante los plugins propios del framework junto con algunos plugins nativos de Kettle.
Limpieza
El proceso de limpieza busca mejorar la estandarización y calidad de los datos previo a la generación RDF. Para realizar este proceso los datos deben pasar previamente por un proceso de análisis que permita distinguir algunos problemas de estandarización asi como errores. En el repositorio mencionado se ha logrado distinguir por ejemplo errores en los autores tal como se detalla a continuación:
Datos adicionales no correspondientes a los nombres propios de autores, por ejemplo:
- Recalde Moreno,Dr. Celso
- Torres Arroba, Fernando Javier Ph.D
Dos nombres pertenecientes a diferentes autores en un solo campo:
- Castro Muñoz, Celia María;Chang Gómez, José Vicente
- Rivas Tarazona, RossanaOsorio Llanos, Ana Cecilia
Nombres completos sin separador entre nombres y apellidos.
- Poma Salazar Mónica Eulalia
- Hidalgo David
Para idiomas se han encontrado dos representaciones diferentes para el idioma español, tal como se muestra a continuación:
- es
- esp
Para solucionar este y otros problemas se requieren flujos de transformación que acondicionen y corrijan los problemas encontrados en los datos, para esto fueron utilizados la gran variedad de plugins nativos de Kettle. Para mayor información acerca de estos procesos revisar la documentación de Pentaho Data Integration. Para este ejemplo en particular revisar transformación de ejemplo.
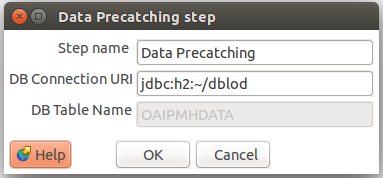
Los datos una vez se han pasado por los flujos de limpieza, deben ser almacenados temporalmente en una base de datos para evitar sobrecargar la memoria. Para realizar este proceso se dispone del plugin “Data Pre-Catching” , al cual debe enviarse los datos de forma normalizada con los siguientes campos:
- Id Record: Identificador del recurso. Ejemplo “oai:localhost:123456789/333” para documento.
- Field: Indica el tipo de dato que contiene el campo Data. Ejemplo “Título”
- Data: Valor del dato de interés. Ejemplo. “Enriquecimiento Semántico…”
El plugin al ser insertado en la transformación automáticamente se cargara con los datos por defecto, por lo que no es necesario realizar ningún cambio en la configuración para su funcionamiento. La base de datos con los datos y otras configuraciones se crearan en la carpeta del usuario tal como se presenta a continuación.
Conversión
Una vez se dispone de los datos y el vocabulario cargado, se procede a generar las reglas de asociación que permitirán generar la descripción en RDF. Para realizar esta actividad se utiliza el plugin “Ontology & Data Mapping”. Dentro de este plugin existen configuraciones generales tales, como:
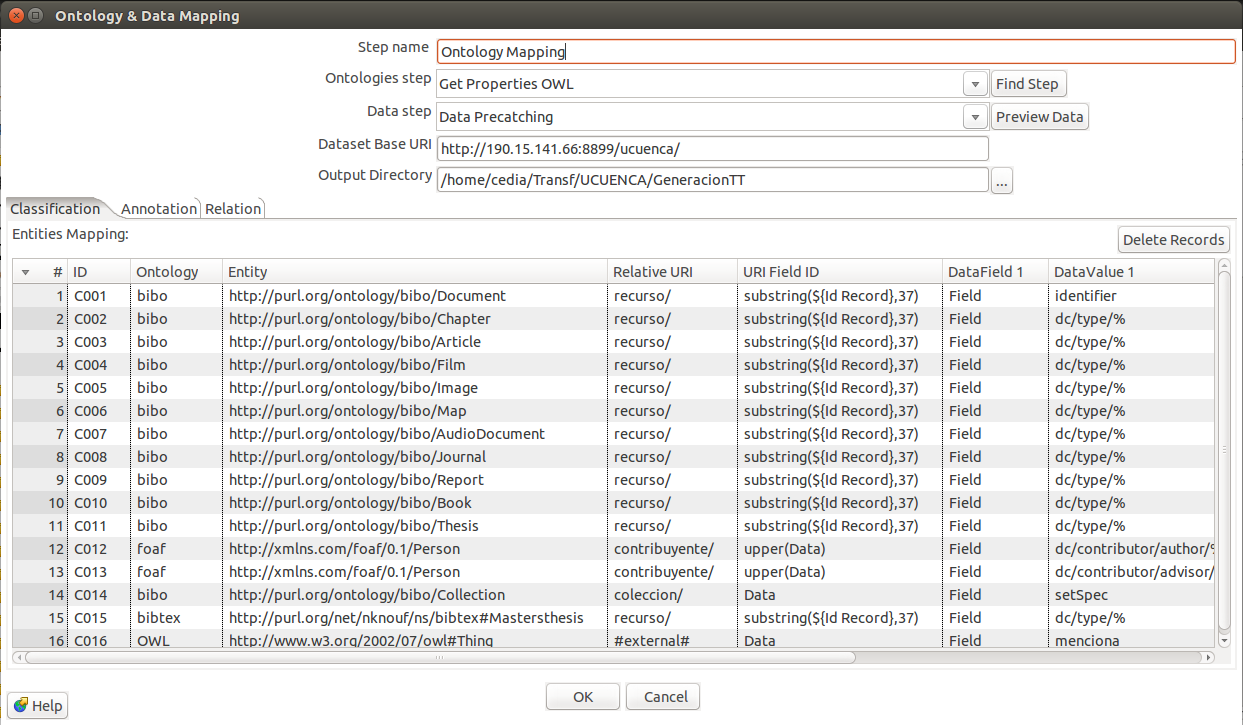
- Ontologies Step: Nombre asignado al plugin de carga de vocabulario. Por defecto “Get Properties OWL”.
- Data Step: Nombre asignado al plugin de cache. Por defecto “Data Precatching”.
- Data Base URI: URI base para todos los recursos. Es recomendable que esta dirección apunte a un servidor accesible y en el cual se puede levantar un servicio (ver sección Explotación) para visualizar los recursos. Para este caso se ha incluido la fuente de origen del recurso para facilitar su identificación.
- Output Directory: Salida del archivo de reglas.
La definición de las reglas entre los vocabularios y los datos constan de 3 apartados:
Clasificación
En este apartado se declaran los recursos existentes en los datos. Por ejemplo Documentos, Personas, Colecciones, etc. Para generar las reglas de asociación este apartado dispone de varios campos.
- ID: Identificador de la regla de clasificación. Puede ser empleado para identificar a los recursos en los siguientes apartados.
- Ontology y Entity: Ontologia y vocabulario con el cual se identificará al recurso.
- Relative URI: URI relativa que identifica al tipo de recurso y se sumara a la URI base.
- URI Field ID: Campo del cual se extraerá el identificador único del recurso. Dentro de este campo se pueden realizar operaciones tales como substring() para tomar únicamente parte de un campo como clave o upper() para pasar el campo clave a mayúsculas. Con este identificador se completara la URI del recurso.
- Data Field y Data Value: Campo y valor que se buscara en cada una de las filas de los datos y por la cual se aplicara dicha regla. Dentro del campo data value se puede usar operadores como “%” que indican que puede ir cualquier valor después del patrón previamente definido.
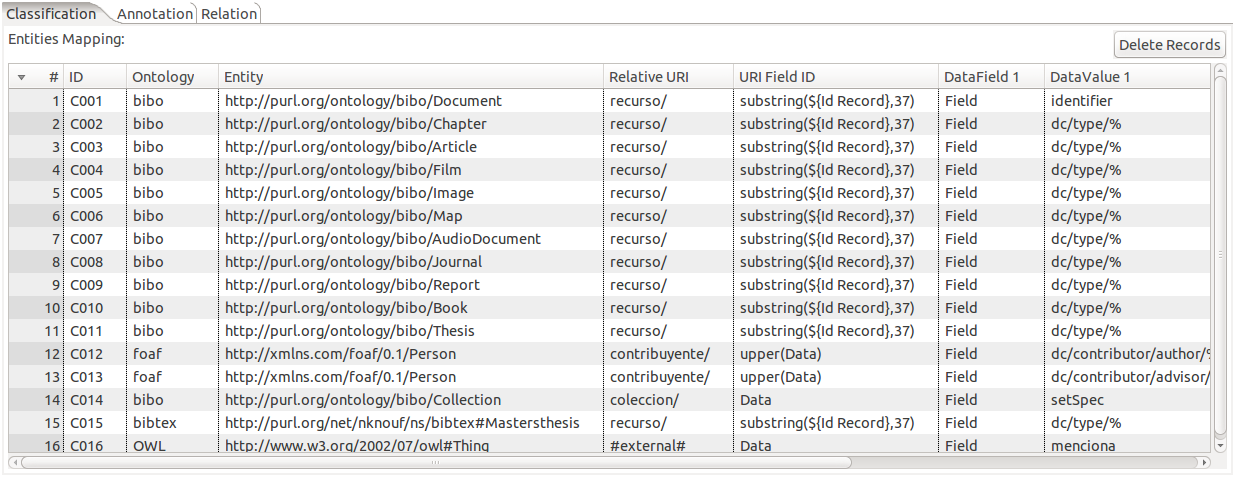
En el primer caso (C001) por ejemplo cuando se encuentre los siguientes datos:
| Id Record | Field | Data |
|---|---|---|
| oai:localhost:123456789/141 | Identifier | oai:localhost:123456789/141 |
Mediante la configuración generada se crea la siguiente tripleta:
| Subject | Predicado | Objeto |
|---|---|---|
| <http://190.15.141.66:8899/ucuenca/recurso/141> | a | <http://purl.org/ontology/bibo/Thesis> |
Para el caso de personas (C012), dada la siguiente entrada:
| Id Record | Field | Data |
|---|---|---|
| oai:localhost:123456789/141 | dc/contributor/author/none | BRITO_RIVAS__MAURICIO_RODRIGO |
Se genera la siguiente tripleta:
| Subject | Predicado | Objeto |
|---|---|---|
| <http://190.15.141.66:8899/ucuenca/contribuyente/ BRITO_RIVAS__MAURICIO_RODRIGO> |
a | <http://xmlns.com/foaf/0.1/Person> |
Anotación
Este apartado permite asociar propiedades de tipo literal a los recursos y dispone de algunos campos similares a los presentados anteriormente:
- ID: Identificador de la regla de anotación.
- Entity Class ID: Permite referenciar al identificador de una regla de clasificación. En otras palabras permite referenciar al recurso declarado.
- Ontology y Property: Ontología y vocabulario con el cual se identificará la relación de propiedad.
- Extraction Field: Campo del cual se extraera el valor de la propiedad generalmente Data.
- Data Field y Data Value: Campo y valor que se buscara en cada una de las filas de los datos y por la cual se aplicara dicha regla en la generación de una relación de propiedad.
- Data Type: Permite seleccionar el tipo de campo con el cual se identificara a la propiedad generada. Ejemplo String.
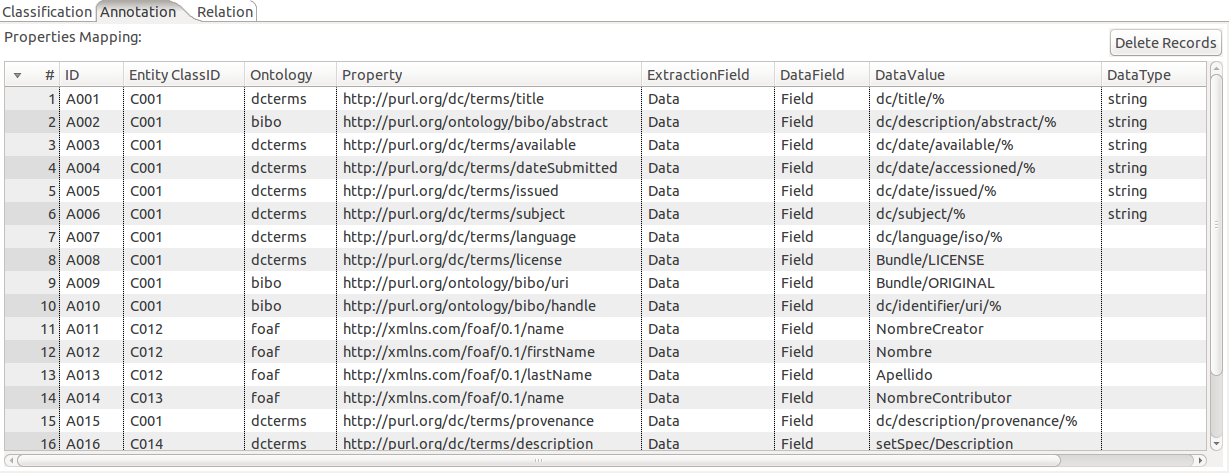
En la regla de asociación (A001) se define la asignación de una propiedad de título al documento declarado en la regla (C001) por lo tanto dado una entrada:
| Id Record | Field | Data |
|---|---|---|
| oai:localhost:123456789/141 | dc/title/es_ES | Diseño e implementación de servicios especializados para el portal … |
Se obtendra la siguiente tripleta:
| Subject | Predicado | Objeto |
|---|---|---|
| <http://190.15.141.66:8899/ucuenca/ recurso/141> |
<http://purl.org/dc/terms/title> | “Diseño e implementación de servicios especializados para el portal del Centro de Documentación Juan Bautista Vázquez”^^<http://www.w3.org/2001/XMLSchema#string> |
En la regla de asociación (A011) se define la asignación de una propiedad de nombre a la persona declarada en la regla (C012), por lo tanto dado una entrada:
| Id Record | Field | Data |
|---|---|---|
| BRITO_RIVAS__MAURICIO_RODRIGO | NombreCreator | Brito Rivas, Mauricio Rodrigo |
*La entrada mencionada fue creada, mediante un proceso de transformación en el proceso de limpieza de datos.
Se obtiene la siguiente tripleta para las propiedades de Personas:
| Subject | Predicado | Objeto |
|---|---|---|
| <http://190.15.141.66:8899/ucuenca/contribuyente/ BRITO_RIVAS__MAURICIO_RODRIGO> |
<http://xmlns.com/foaf/0.1/name> | “Brito Rivas, Mauricio Rodrigo” |
Relation
En este apartado se definen relaciones entre los recursos definidos previamente. Para esto cuanta de los siguientes campos:
- ID: Identificador de la regla de relación entre recursos.
- Entity ClassID 1: Identificador del primer recurso. Desde el cual parte la relación.
- Ontology y Property: Ontología y vocabulario que representa a la propiedad que relaciona los recursos.
- Entity ClassID 2: Identificar del segundo recurso. Al cual llega la relación.
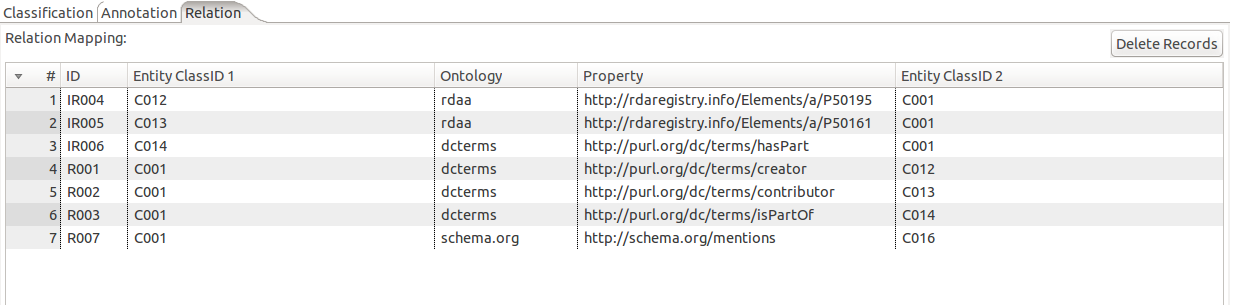
En la regla de relación (R001) se especifica la relación de los recursos tipo documentos (C001) con el de personas (C012) mediante la relación de creador. Esto significa que dada la siguiente entrada:
| Id Record | Field | Data |
|---|---|---|
| oai:localhost:123456789/141 | dc/contributor/author/none | BRITO_RIVAS__MAURICIO_RODRIGO |
Se genera la tripleta:
| Subject | Predicado | Objeto |
|---|---|---|
| <http://190.15.141.66:8899/ucuenca/ recurso/141> |
<http://purl.org/dc/terms/creator> | <http://190.15.141.66:8899/ucuenca/ contribuyente/BRITO_RIVAS__MAURICIO_RODRIGO> |
Existe otro tipo de relaciones que ocurren de forma inversa a las declaradas, es decir van desde el recurso 2 al recurso 1. Para declarar estas relaciones basta con definir una relación como IR. Adicionalmente hay que invertir el orden del recurso 1 y el 2 tal como se puede apreciar en la relación (IR004).
Dada la misma relación anterior da como resultado la siguiente tripleta.
| Subject | Predicado | Objeto |
|---|---|---|
| <http://190.15.141.66:8899/ucuenca/ contribuyente/BRITO_RIVAS__MAURICIO_RODRIGO> |
<http://rdaregistry.info/ Elements/a/P50195> |
<http://190.15.141.66:8899/ucuenca/ recurso/141> |
Para obtener finalmente el archivo en formato RDF se debe utilizar el plugin “R2MLtoRDF2” que mapea las reglas definidas con los datos. Algunos de los datos previamente definidos pueden cargarse en este plugin automáticamente mediante el botón “Retrieve DBConnection From Input Step”. Algunos campos que puede requerir definirse son:
- RDF Output File: Ruta del archivo RDF de salida.
- RDF Output Format: Formato del archivo RDF. Ejemplo Turtle o RDF/XML.
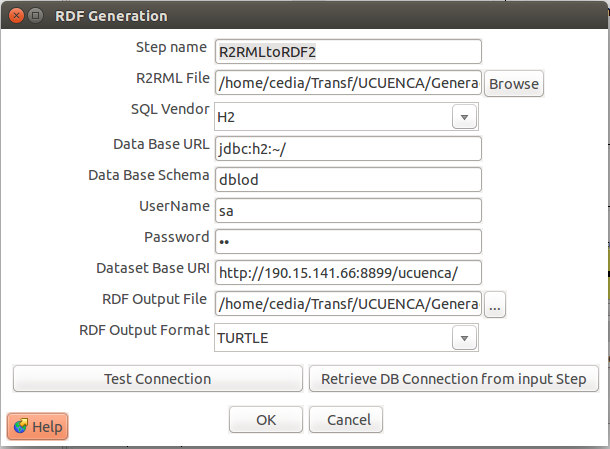
Para obtener el archivo como RDF, se debe ejecutar el proceso de transformación hasta este punto. Posteriormente a este paso se puede proseguir con el etapa de publicación.
Publicación
Para dar visibilidad a los datos obtenidos y permitir su acceso al público, se pueden almacenar los datos en un triplestore como FUSEKI. Para desplegar este servicio el framework dispone del plugin “FUSEKI LOADER” el cual debe configurarse con los siguientes parámetros.
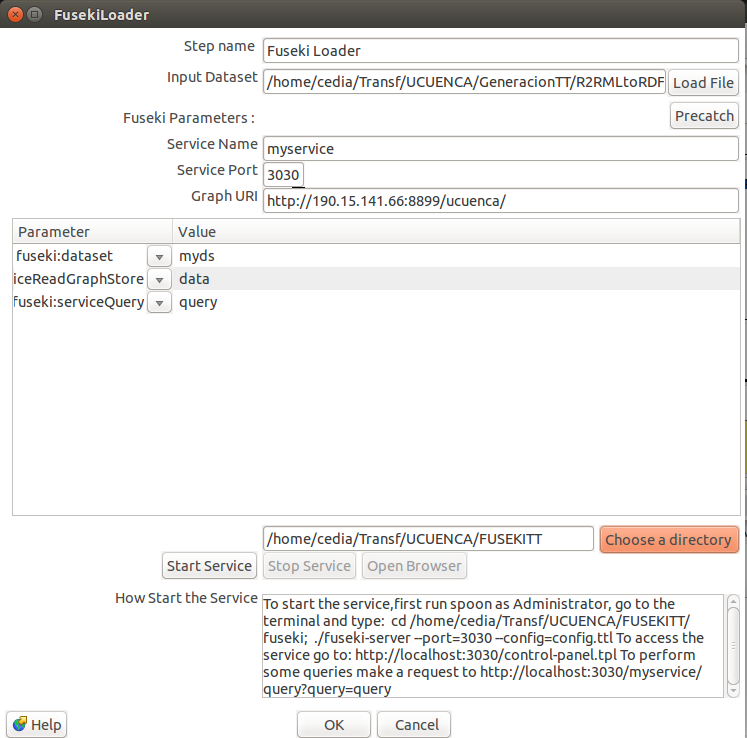
- Input Data Set: Archivo RDF obtenido del paso anterior.
- Service Name: Nombre del servicio que formara parte de la URL de acceso al endpoint SPARQL. Por defecto “myservice”
- Service Port: Puerto por el cual se levantara el servicio de SPARQL Endpoint. Por defecto 3030.
- Graph URI: URI del grafo que contendrá el conjunto de datos.
- Choose a Directory: Directorio de salida de los archivos y dependencias.
Algunos de los campos se cargan automáticamente mediante el boton “Precath”. En la tabla posterior se puede configurar ciertas características como permisos de modificación de los datos.
- Fuseki:serviceReadGraphStore : Habilita permisos únicamente de lectura. Por defecto.
- Fuseki:ServiceUpload: Permite subir nuevos dataset al fuseki.
- Fuseki:ServiceUpdate: Habilita el servicio de actualización de los datos.
- Fuseki:ServiceReadWriteGraphStore: Habilita permisos de lectura y escritura a través del endpoint.
Una vez configurado se requiere ejecutar una vez el proceso de transformación para que se generen los archivos necesarios para poder iniciar el servicio. Posteriormente a este proceso se puede inicializar el servicio en consola mediante los siguientes pasos:
- Trasladarse a la carpeta en la que se creo una instancia de fuseki.
- Ejecutar ./fuseki-server -port 3030 -config=config.ttl
- Acceder al servicio http://localhost:3030
- Abrir el puerto y asignar al computador una IP publica para que pueda ser accesible a través de la web.
Es posible cambiar el puerto por el cual acceder al servicio, por lo que en lugar de 3030 puede emplearse algún otro puerto seleccionado.
Enlace
El proceso de enlace permite establecer vínculos entre los recursos de modo que la información disponible entre varias fuentes pueda ser relacionada. En el caso de repositorios se ha notado que la mayor probabilidad de enlace entre recursos ocurre entre autores, puesto que pueden trabajar realizando obras en varias instituciones. Debido a esta razón se ha creado el plugin de linking Silk workbench que emplea los nombres de los autores junto con las obras asociadas a los mismos para tratar de determinar si dos autores representan la misma persona. Este proceso se lo puede dejar casi al final, debido a que previamente se requiere haberse realizado el proceso de publicación para cada una de las fuentes que requieran enlazarse. Los datos deben encontrarse publicados debido a que el plugin generado utiliza los servicios de Sparql Endpoint para facilitar su configuración. Para configurar este plugin se disponen de los siguientes campos:
- Insert first Endpoint y Graph first Endpoint: URI del primer endpoint y su grafo.
- Insert Second Endpoint y Graph Second Endpoint: URI del segundo endpoint y su grafo.
- Thresold for metrics: Umbral para la comparación sintáctica (SILK).
- Thresold for refine process: Umbral para la comparación semántica.
- Linking File Output: Directorio de Salida.
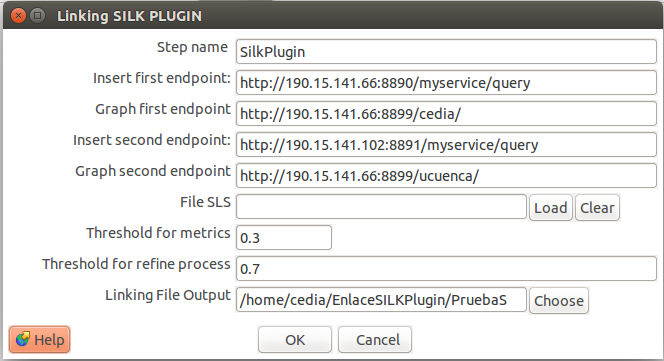
En este caso se ha buscado enlaces entre los autores del endpoint de la universidad de Cuenca y la institución de CEDIA, la cual previamente ya se había realizado el proceso de publicación de sus datos. Una muestra de los autores que se encontraron como equivalente se resumen a continuación.
| Universidad de Cuenca | Cedia |
|---|---|
| Delgado Suconota, María Fernanda | Delgado, María Fernanda |
| Illescas Riera, Raquel Guadalupe | Illescas Riera, Raquel |
| Ortíz Segarra, José | Ignacio Ortíz Segarra, José |
| Andrade, Gabriela | Andrade, Gabriela |
| Espinoza, Mauricio | Espinoza, Mauricio |
| Saquicela, Víctor | Saquicela, Víctor |
Explotación
Para mejorar la visualización de los recursos frente a los usuarios se puede emplear el plugin “ELDA Loader”. Este plugin utiliza ELDA API para generar una página de descripción de los recursos a los cuales el usuario puedan acceder mediante su URI. Para configurar este plugin el servicio del SPARQL Endpoint debe encontrarse funcionando. Dentro de las configuraciones de este plugin se encuentran:
- SPARQL Service: URI del servicio de endpoint SPARQL
- BASE URI: URI del grafo en el que se almacenan los datos
- Entities: Presenta las clases disponibles en el endpoint.
- Properties: Presenta las propiedades de cada una de las clases disponibles.
- Output Directory: Directorio de salida en la que se creara una estancia de ELDA.
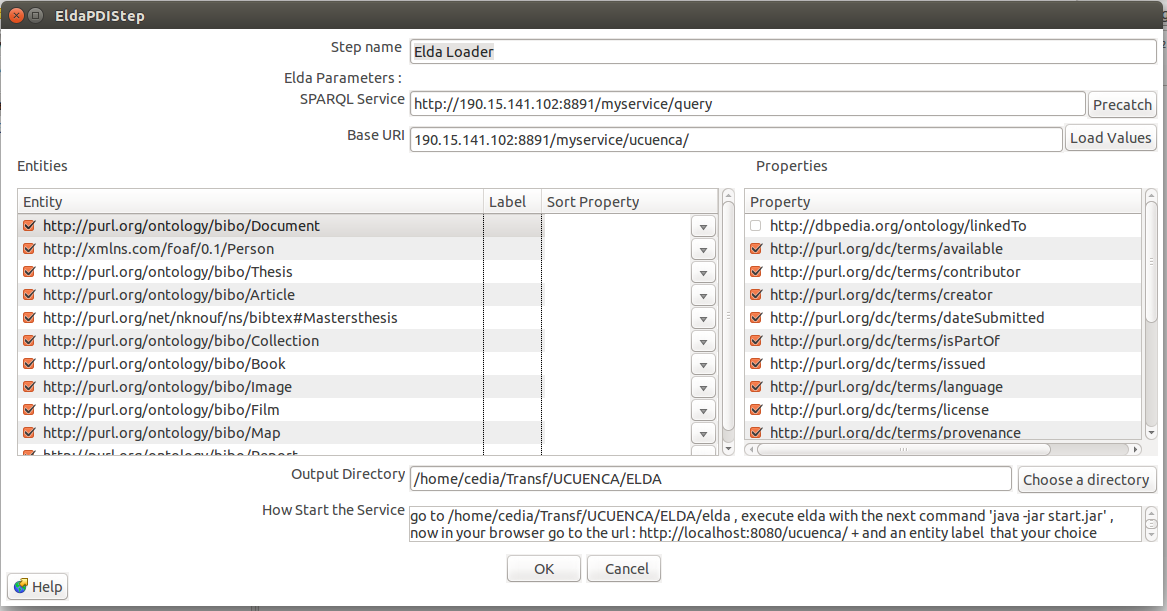
Una vez se ha configurado el plugin es necesario correr la transformación para generar una instancia de ELDA. Posteriormente, se debe seguir los siguiente pasos:
- Trasladarse al directorio de salida
- Ejecutar el comando java -jar start.java
- Una vez inicializado abrir el navegador a la dirección http://localhost:8080/ + fuente + Tipo de Recurso. Ejemplo http://localhost:8080/ucuenca/Document